
티스토리 뷰
이름에서 알 수 있듯 feature matching 모델이다. feature matching이란 두 이미지 사이에서 같은 특징을 찾는 점을 연결해주는 것이다. 이 task를 딥러닝에서 수행하게 되면서 image feature를 찾기보다는 한 이미지에서 다른 이미지로 대응되는 점을 찾는 것으로 변화하게 되었다. feature matching을 통해 homography나 extrinsic parameter를 구하는 등의 task들을 이런 방식의 matching으로도 수행 가능하다.
이후 나온 3DG-STFM과 같은 여러 논문들이 이 방식을 기반으로 연구했다.
Method overview

먼저 모델을 빼고 흐름을 살펴보자.
두 이미지 A와 B가 있다.
- 두 이미지를 동일한 크기의 칸으로 나눈다.
(논문에서는 그림1보다 더 작은 칸(80x80)으로 나누었지만 편의상 5x5로 나누었다.) - 이미지 A의 각 칸이 이미지 B의 어느 칸에 대응되는지 찾는다.
(빗금 친 부분으로 볼 수 있다) - 이미지 A의 각 칸을 대표하는 점(왼쪽 상단)이 이미지 B에서 어느 점에 대응 되는지 찾는다
Model Pipeline

LoFTR은 크게 네 부분을 나누어 볼 수 있다. Local feature를 뽑는 local feature CNN, Coarse-level feature를 뽑는 Coarse-Level Local Feature Transform, coarse feature로 대응되는 칸을 찾는 Matching Module, 특정 대응 점을 찾는 Coarse-to-Fine Module이 있다. 여기서 coarse의 의미는 이미지에서 나눈 칸 단위이고, fine은 보다 세부적인 점 단위라고 보면 된다. 기호 상으로는 ~이 coarse, ^가 fine을 의미한다.
Local Feature CNN
backbone으로 feature map을 뽑는 단계이다. 코드 상에서는 resnet을 사용했다. down scaling을 3번 하여 input 이미지의 1/8 크기를 가지는 $\widetilde{F}^{A}$, $\widetilde{F}^{B}$와 여기서 두 번 upscaling해서 이미지의 1/2 크기를 가지는 $\hat{F}^{A}$, $\hat{F}^{B}$구한다. coarse-level local feature transform 에서 1/8 feature map의 한점(채널 방향은 고려하지 않는다)은 이미지의 한 칸을 의미하게 되고, 따라서 이미지는 8x8 픽셀 크기로 나누어졌음을 알 수 있다.
Coarse-Level Local Feature Transform
이 단계에서는 CNN을 통해 나온 1/8 feature map을 사용해 각 칸의 feature vector를 구한다. feature map을 flatten하여 positional encoding(DETR과 같은 방식)을 더한 후 LoFTR Module에 반복적으로 넣어 이미지 A,B의 feature vector들을 각각 구하게 된다.
LoFTR Module
LoFTR Module은 self-attention layer와 cross-attention layer로 구성되어 있다. Self-attention layer는 하나의 이미지의 feature($f_{i}$)를 key, query, value로 넣어 각 이미지의 특징을 찾는다. Cross-attention layer는 두 이미지 중 하나의 feature($f_{i}$)가 query로 들어가고, 다른 이미지의 feature($f_{j}$)가 key와 value로 들어간다.

이 모듈은 attention의 속도를 높이기 위해 softmax를 사용하지 않고, elu로 대체했다. 그러면 attention이 linear해 지고, key와 query를 먼저 계산하는 대신 key와 value를 먼저 계산할 수 있게 된다(결합 법칙). 이 방식을 사용하면 $O(N^{2})$이었던 시간 복잡도가 $O(N)$이 된다고 한다.
이 방식은 이미 다른 논문에서 제안되었던 것이라 해당 논문을 참고하면 될 것 같다.
Matching Module
위에서 계산한 $\widetilde{F}^{A}_{tr}$, $\widetilde{F}_{tr}^{B}$은 여전히 flatten한 형태를 가지고 하나의 점이 이미지에서 하나의 칸을 의미한다. 두 이미지에서의 모든 점들을 곱하여 이미지A의 모든 칸이 이미지 B의 모든 칸과의 관계를 구하며, 이를 similarity라 칭한다(수식으로는 $S (i,j) = 1 · ⟨FA(i),FB(j)⟩$). 점들이 이미지마다 N개 존재한다고 하면, NxN행렬의 similarity를 얻게 된다.
이후 matching을 하는 방법은 두 가지가 있다. 먼저, Optimal transport를 이용하는 방법은 similarity를 cost로 사용한다.
Dual-softmax라고 부르는 방법은 softmax를 사용해 matching probability($Pc$)를 구한다. $Pc(i, j) = softmax (S (i, ·))_{j} · softmax (S (·, j))_{i}$ 의 수식을 사용한다. A이미지의 칸 $i$와 B이미지의 모든 칸의 feature vector의 similarity를 softmax를 취해 확률을 구하고, 이미지 B의 점 $j$에 대해서도 같은 방식으로 확률을 구한다. 그리고 이 두 확률을 곱해 최종 matching probability를 얻는다. 이 matching probabilty에 threshold와 mutual nearest neighbor를 사용해 outlier의 가능성이 있는 match를 제거하여 점들을 매칭한다.
Coarse-to-Fine Module
칸을 매칭했으니 좀 더 세부적으로 점을 매칭해야한다. 코드상으로 보면 각 칸의 왼쪽상단을 기준점($\hat{i}$)로 하여 다른 이미지의 어느 점에 해당하는지 찾는다. 이 모듈의 input으로는 CNN으로 뽑은 1/2 feature map을 사용한다. 이 feature map은 coarse-level에서 사용했던 feature map에 비해 4배 크므로, 원본 이미지에서의 한 칸이 4x4가 됨을 알 수 있다. 따라서 4x4를 window size($w$)로 정한다. 이 window 크기로 1/2 feature map에서 한 칸 씩 patch를 뜯어 한 점을 구한다. 이미 coarse-level에서 매칭된 칸이 있으므로 해당하는 칸의 patch를 가져온다. 각 patch를 LoFTR Module의 input으로 넣고, $N_{f}$번 반복한다.
반복을 통해 나온 4x4 feature map 두 개 중 A이미지의 map의 중심점의 feature vector를 B이미지의 feature map과 곱해 4x4의 correlation을 구하고, softmax를 취해 이미지 B의 patch의 각 점이 가지는 확률을 구한다.
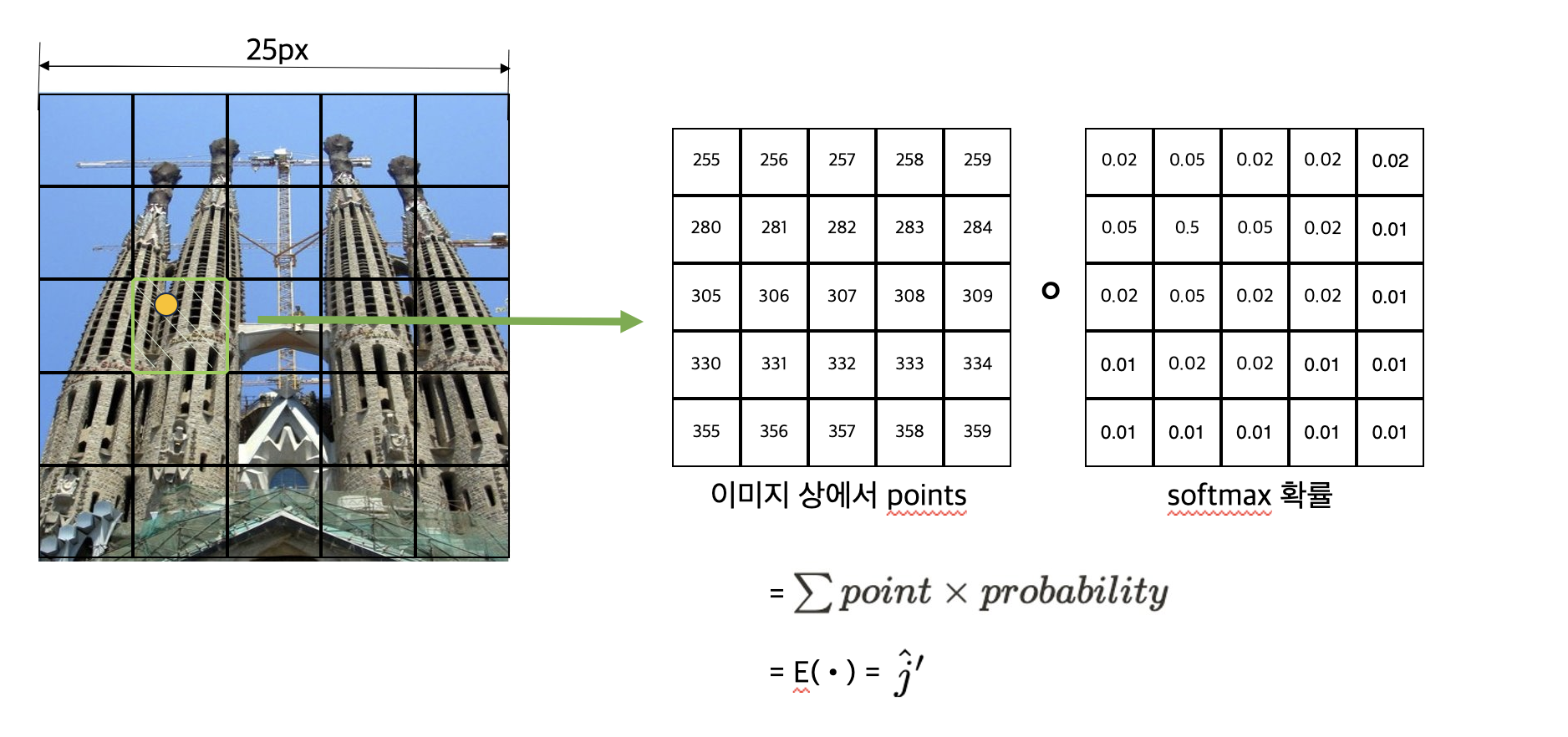
이렇게 구한 확률을 element-wise로 곱하여 이미지B의 점 $\hat{j}^{'}$을 구한다(그림4).
Loss
coarse-level의 칸 매칭, fine-level의 점 매칭 loss를 각각 구해 더해 최종 loss를 구한다.
Coarse-level loss는 dual-softmax를 사용해 확률을 구했을 경우 negative log-likelihood loss를 사용하여 구한다.
$$
\mathcal{L}_{c}=-\frac{1}{|\mathcal{M}_{c}^{gt}|}\sum_{(\widetilde{i},\widetilde{j})\in \mathcal{M}_{c}^{gt}}\mathrm{log}\mathcal{P}_{c}(\widetilde{i},\widetilde{j})
$$
Fine-level loss는 gt와 L2 norm을 이용해 구한다. $\sigma^{2}(\hat{i})$은 대응되는 heatmap의 총 분산을 의미한다.
$$
\mathcal{L}_{f}=-\frac{1}{|\mathcal{M}_{f}|}\sum_{(\hat{i},\hat{j})\in \mathcal{M}_{f}}\frac{1}{\sigma^{2}(\hat{i})}||\hat{j}^{'}-\hat{j}^{'}_{gt}||_{2}
$$
How to make GT
이 논문은 MegaDepth와 ScanNet 데이터 셋을 이용하는데 Megadepth를 기준으로 설명하고자 한다.
MegaDepth는 야외를 촬영한 이미지로 구성되어 있고, meta data로 intrainsic과 extrinsic parameter, depth map, 이미지 Pair(이건 데이터 셋에 있는건지, 모델에서 만든건지는 잘 모르겠다.)가 있다.
GT를 만드는 과정은 코드 상으로는 supervison이라고 명시되어 있는데, 이미지A에서 칸을 대표하는 모든 점을 이미지 B로 projection하는 과정이다. 이를 이해햐려면 geometry에 대해 어느정도 알아야 한다. (geometry에 대해서는 추후 정리해 링크를 연결하기)
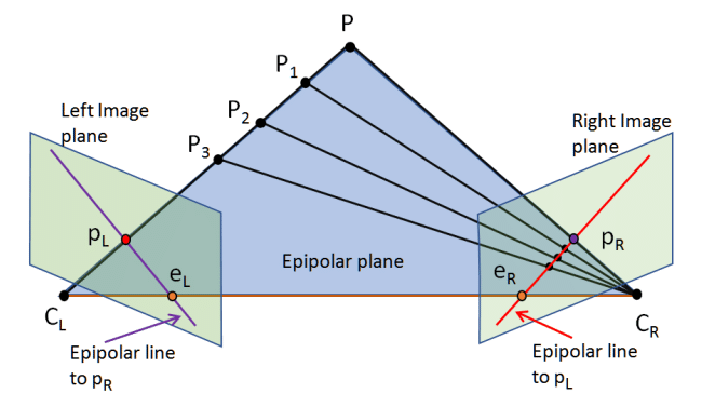
이미지의 point를 world coordinate으로 옮기면 그림4에서 보듯이 world의 하나의 점이 아닌 line이 된다. 이 line 위의 어느 점인지 알 수 없는 것이다. 따라서 depth map을 이용해 line 위에 어느 점인지 찾는다. 그러면 해당 점을 다른 이미지(B)로 projection할 수 있다. 그러면 다른 이미지 위에서 어느 점에 대응되는지 찾게 되는 것이다.
이렇게 점을 구하고 나면 해당 점을 포함하는 칸을 구하고, 해당 칸이 이미지 A와 이미지 B가 대응되는 칸이 된다. 이렇게 매칭된 칸들의 집합이 $\mathcal{M}_{c}^{gt}$이고, 점들의 집합이 $\mathcal{M}_{f}$이다.
'Deep Learning' 카테고리의 다른 글
- Raspberry Pi
- feature
- conditional GAN
- AI
- 신호처리
- OS
- Deep learning
- 디지털신호처리
- MLOps
- Depth estimation
- Building Basic GAN
- design pattern
- 3d object detection
- ML Pipeline
- mode collapse
- machine learning
- pcb
- Gan
- deeplearning
- image
- 딥러닝
- Operating System
- DSP
- controllable GAN
- depthmap
- 운영체제
- ML
- depth
- TRACKING
- Generative Model
- Total
- Today
- Yesterday
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |