
티스토리 뷰
※ Coursera의 Build Basic Generative Adversarial Networks (GANs) 강의를 듣고 작성한 글입니다.

Week 1에서는 GAN의 기본적인 구조에 대해 학습합니다.
Generative Model 이란?

이름 그대로 무언가를 생성하는 모델을 generative model이라고 말합니다. 이를 discriminative model과 비교해볼게요.
Discriminative model은 개와 고양이를 나누듯 class를 나누는 작업을 수행합니다. 어떤 이미지 feature가 input으로 들어가면 개인지, 고양이인지하는 class로 output이 나온게 됩니다.
Generative model은 이미지를 생성해주는 모델입니다. input과 output이 generative model과는 반대라는 것을 볼 수 있죠. Random noise도 함께 들어가는데 이를 통해 생성되는 이미지의 다양성이 생깁니다. 그리고 class가 하나 뿐이라면 조건부 확률에서 class인 $Y$가 사라지게 됩니다.
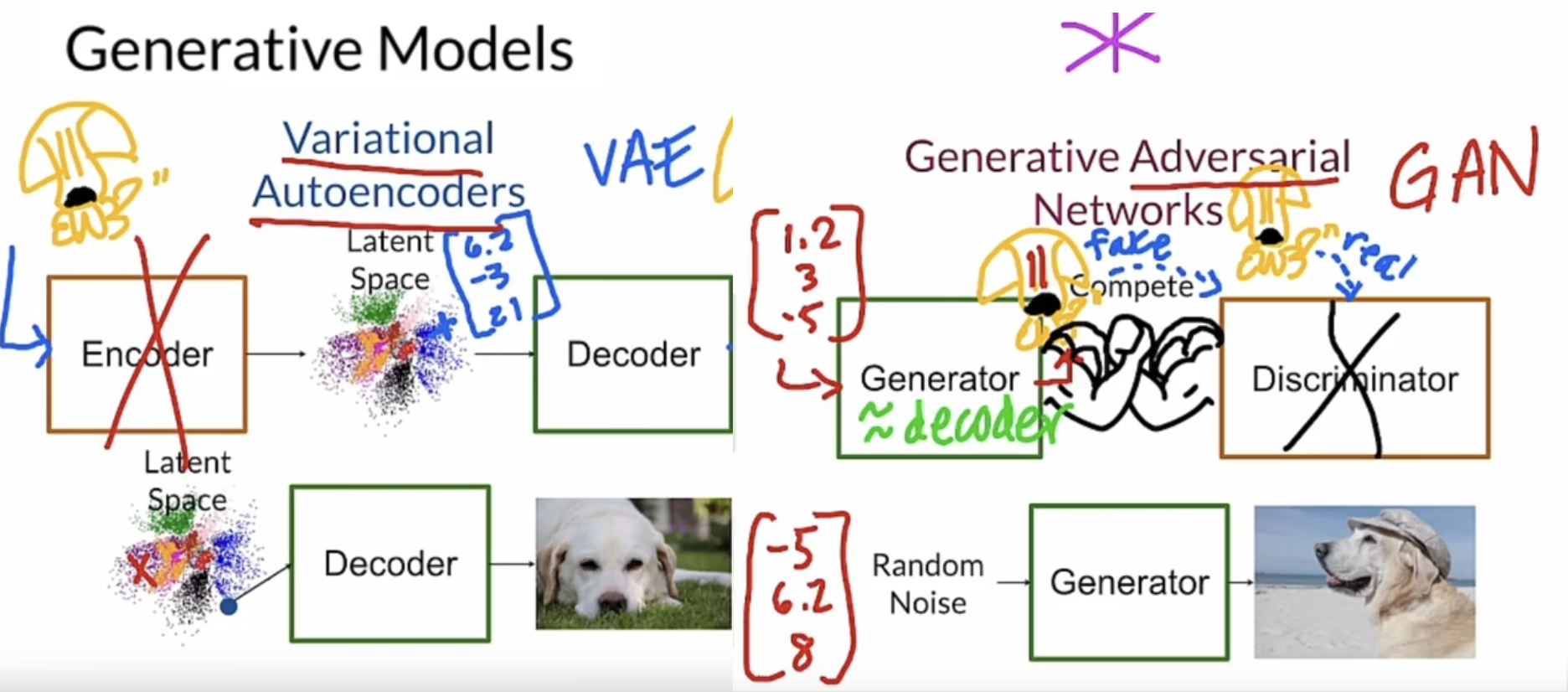
Generative Model에는 크게 두 가지 종류가 존재합니다. (지금은 Diffusion이 추가되었지만 이 강의가 나온 시점은 더 예전인듯.)
Variational Autoencoder와 Generative Adversarial network가 있습니다.
Variational Autoencoder는 encoder를 통해 이미지를 latent space로 투영하고 decoder를 통해 다시 이미지로 복원시켜 학습합니다. 그리고 이미지 생성은 latent space의 임의의 지점을 정해 decoder를 통과시켜 이루어집니다. Generative model은 GAN을 의미하므로 아래에서 알아보도록 하겠습니다.
GAN의 기본적인 구조
GAN은 두 가지 모델로 구성되어 있습니다. 이미지를 생성하는 Generator와 이미지가 원본(real)인지 생성된 이미지(fake)인지 판단하는 Discriminator 입니다. Generator와 discriminator는 번갈아 freeze되어 학습됩니다. Generator는 discriminator를 잘 속일 수 있는 이미지를 생성하는 방향으로, discriminator는 generator가 생성한 이미지를 가짜라고 잘 판한다는 방향으로 학습됩니다. 학습된 모델로 이미지를 생성할 때에는 generator만 사용합니다.
Discriminator
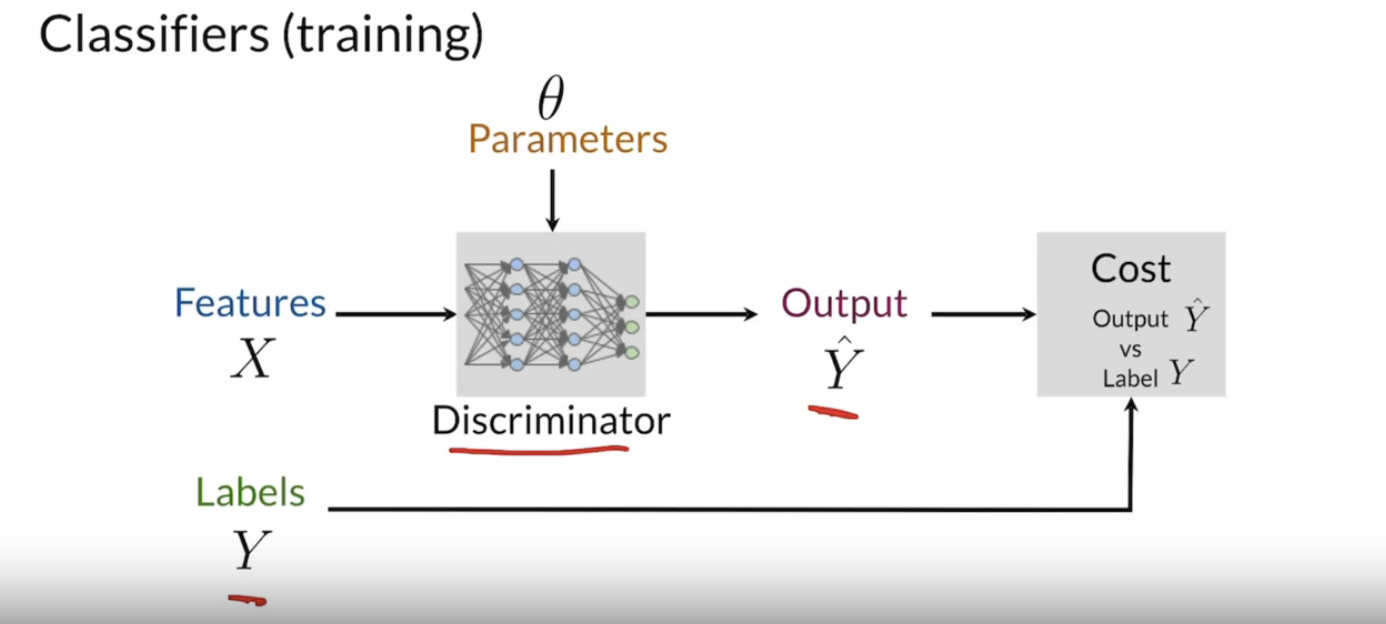

Discriminator는 real과 fake 두 가지 class를 가지고 classification을 수행하는 부분입니다. 학습은 feature를 넣어 나온 classification 결과를 label과 비교하여 cost를 계산하여 진행됩니다. 여러 classification과 마찬가지로 classification 결과는 확률로 표현되어 모델이 생성된 이미지를 어느정도 가짜라고 판단했는지 알 수 있습니다.
Generator

Noise를 input을 넣어 generator를 통해 이미지를 생성합니다. 생성된 이미지($\hat{X}$)를 discriminator에 넣어 real인지 fake인지에 대한 output으로 cost를 구해 generator의 parameter를 업데이트하여 학습합니다.
Loss Function
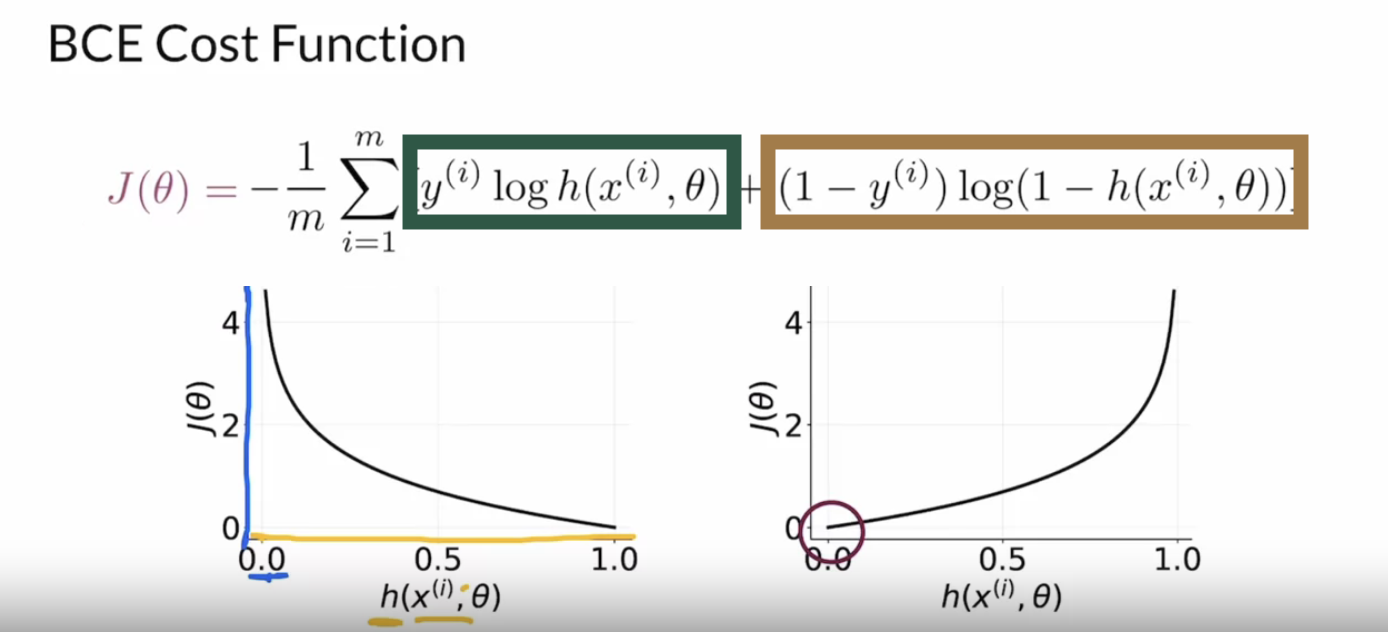
Binary cross entropy를 loss로 사용합니다. Function을 부분부분 나누어 알아봅시다.
먼저 1/m 부분은 모든 데이터의 평균을 의미합니다.
$\sum$ 뒤의 항은 크게 두 가지고 나눌 수 있습니다. 앞쪽 부분(초록색 상자)는 정답이 real($1$)일 때 cost를 계산할 수 있게 해주고, 뒤쪽 부분(갈색 상자)는 정답이 fake일 때 cost를 계산할 수 있게 해줍니다.
정답이 real이면 $y^{(i)}$는 1입니다. 이 때 feature x를 통해서 나온 결과 값이 잘 학습되어 $h()$가 1에 가깝다면 초록색 상자의 식은 0의 가까운 값을 가지게 됩니다. 하지만 학습이 잘 되지 않아 0에 가까워질수록 -inf의 값에 가까워지게 됩니다. 갈색 상자 부분은 $1-y$가 0이므로 log식에 상관 없이 0의 값을 가지게됩니다.
정답이 fake일 때는 반대로 갈색 상자 부분의 $1-y$가 $1$이 되고, 학습이 잘 되지 않으면 $1-h$가 $0$에 가까워져 -inf의 값을 가지게 됩니다.
딥러닝 모델은 일반적으로 큰 cost를 줄이는 방향으로 학습하므로 -inf를 inf로 바꿔주기 위해 cost항의 맨 처음에 -를 붙여줍니다.
GAN의 활용

GAN은 매우 빠르게 발전해왔습니다. 흑백에서 고화질까지 오는데 4.5년이 걸렸다고 합니다. 이미지 생성 뿐만 아니라 style을 바꿔주는 task에 대한 성능도 좋습니다. 그리고 그림을 그릴 영역을 나누어주면 그에 맞게 이미지를 생성해주는 모델, 3D를 생성하는 모델도 있습니다.
(오류나 개선점이 있다면 댓글로 알려주세요!)
'Deep Learning' 카테고리의 다른 글
| ReST (0) | 2024.02.16 |
|---|---|
| Building Basic GAN, Week2 - Lecture (0) | 2024.02.03 |
| Enhancing Multi-Camera People Tracking with Anchor-Guided Clustering and Spatio-Temporal Consistency ID Re-Assignment (1) | 2024.01.20 |
| LoFTR: Local Feature matching with TRansformers (1) | 2024.01.14 |
| PRML 4. 선형 분류 모델(Linear Models for Classification) (0) | 2022.06.05 |
- conditional GAN
- Gan
- AI
- 디지털신호처리
- pcb
- deeplearning
- controllable GAN
- depthmap
- Building Basic GAN
- mode collapse
- Raspberry Pi
- MLOps
- OS
- 딥러닝
- Depth estimation
- design pattern
- ML
- Deep learning
- 운영체제
- 신호처리
- depth
- 3d object detection
- DSP
- ML Pipeline
- Generative Model
- feature
- image
- machine learning
- Operating System
- TRACKING
- Total
- Today
- Yesterday
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |